Evaluate and improve your RAG with our metrics
Boost accuracy of your LLM app with foresight.
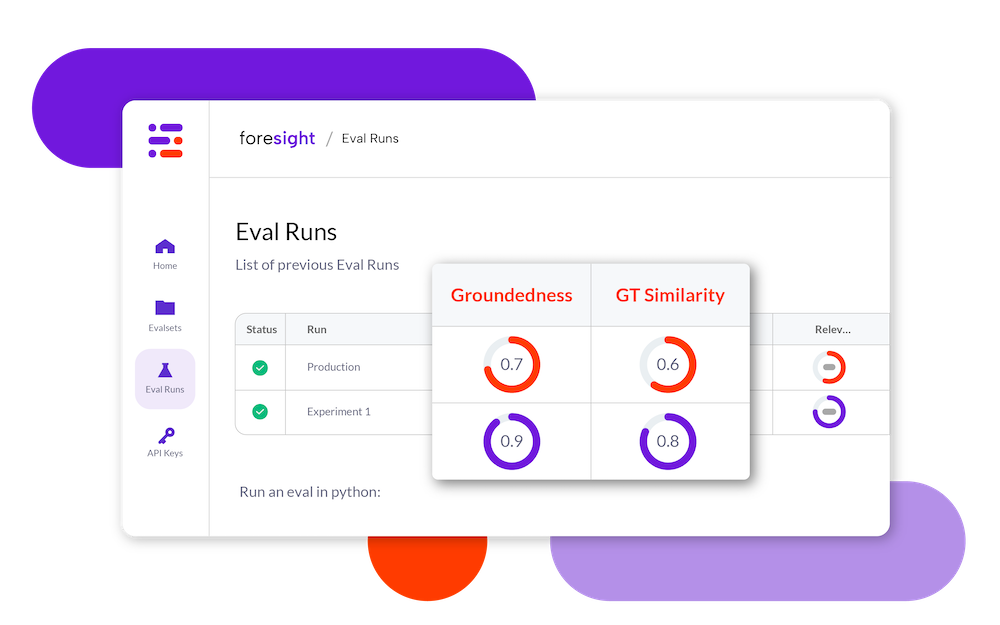








.png?width=1200&length=1200&name=chatbot_examples_report_800px%20(1).png)
Basic
Free
-
 Up to 1’000 evaluated queries per month
Up to 1’000 evaluated queries per month
-
1 seat per company
-
Basic support
-
No credit card required
-
All platform features
Enterprise
-
Unlimited volume
-
Unlimited seats
-
Premium support & custom setup
-
Hosted or self-hosted deployment
-
